Message brokers - common design problems and how to solve them


In the previous part of this article series I presented an approach that can help you decide if a message broker is something you need in your application. To have a full picture you need to answer one more question: what is the cost of implementing such a system? (And we’re not talking about finance). Introducing queues means that we have to face a number of additional problems that we do not encounter with less complicated applications. It is worth being aware of these limitations before implementing a queueing system and this blog post it's exactly what I'll be walking you through.
Preventing the issues caused by increased complexity
The first and in my opinion the most important problem for applications using a message queue is increased complexity. Many developers are so accustomed to the traditional monolithic approach that it might initially be hard to change their perspective. Without the right level of attention, knowledge and guidance the project can quickly run into troubles. So what can we do to prevent the issues surrounding this?
Many developers are so accustomed to the traditional monolithic approach that it might initially be hard to change their perspective. Without the right level of attention, knowledge and guidance the project can quickly run into troubles.
1. Program flow / context isn’t explicitly declared anywhere - when you take a look at the codebase of the ‘distributed’ application you will easily see the bigger picture. But when you focus on a specific part of the code and try to add a new feature, you might find that you don’t know what influence your change can have on the other parts of the system. There is no easy way of telling where the consumers are or what they are doing. And particularly, as your system grows and there are more and more messages added, without considering the overall architecture, it can quickly become more difficult to understand the dependencies between components.
2. Additional infrastructure to maintain - Instead of maintaining a single application, we have at least two, plus some kind of message broker (be it a separate system, a separate process, or some kind of database on which the queuing system is based). This causes additional deployment problems. The process is also more difficult to maintain and there may be problems such as: you have some messages in the queue, you want to deploy a new version of the application and migrate some databases dependent on the service - but you’re not sure what will happen to the messages that are already in the queue and how you can perform your operation without spoiling anything. The more applications there are to maintain, the more challenges appear.
3. More complicated code on the client side - handling the results of asynchronous tasks on the client side is also a bit more complicated. There is no more simple request - response communication. You have to either implement websockets or ping a server from time to time to get a result. This in turn means: more system states to handle and to service.
4. Testing - both automatic and manual tests are more complex. Manual tests can be harder because sometimes it’s more difficult to see the immediate results of the performed actions. Imagine that you click a button and you expect to see some result in the application, but the request sent only triggered an action to perform in the background and the result will be visible a bit later. In this situation you might receive 200 status from the first response, but if the expected result won’t appear, you have only limited possibilities to check what is going on. It is for sure much harder to realize where the problem is. Maybe the task in the background failed, which you might not immediately be aware of. It might even be the case that it’s not a failure, but just a task which took more time to process for some external reason - again you don’t know it.
Messages order aka “sequence issue”
Generally speaking: message order is not guaranteed. Especially when we will have more than one instance of the specific service (consumer). Messages are processed in parallel and there is no synchronization between consumers. Each consumer has no knowledge of others running in parallel. Each consumer can crash or slow down at any point in time and it’s difficult to prevent such situations.
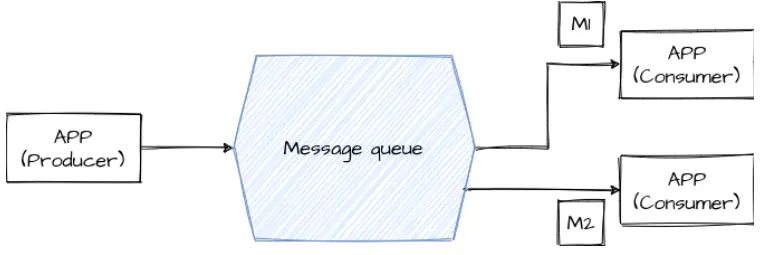
Let’s assume here a simple situation (maybe it’s a wrong use case and we should avoid such design but these situations do happen). We have a single producer, single message queue and two consumers listening to this queue. The producer creates two messages: 1. Update product availability and 2. Inform clients via email that the product is available. Depending on the state of the consumers, each of these messages has an equal chance of being sent to either one of the consumers. Now, the order of these messages being processed depends on how fast each consumer is and how much time it takes to complete task1 and task2.
We can see at least two failure scenarios here:
The race condition: If updating the availability process will fail for some reason, we can inform the client that the product is available when basically it isn’t - this is typically known as the race condition which can produce wrong results.
An email sent twice: If for whatever reason there is a fault within the process of sending an email, then the message will be requeueued and can be processed by the second consumer. However, this consumer doesn't know in which state the previous process has been finished - has the email been already sent or not? For this reason, the email may end up being sent twice.
Avoiding problems with the order of messages
Depending on the nature of your design, you may have further problems of this nature to resolve. So what can be done, to avoid problems with the order of messages:
- Limit the number of consumers to a single thread processing a single message at time and handle the errors wisely.
- Assume in each operation that messages can arrive in a random order and plan solutions around this.
- Build a specialized consumer which consumes only a single type of messages.
- Group your messages: Some systems such as ActiveMQ allow you to create ‘groups’ of messages. This mechanism splits the messages on a queue into parallel virtual queues to ensure that messages from a single group will have their order preserved.
Avoiding incorrect design traps
Message queue based systems require you to think differently about the design of your solution as they differ from the traditional approach based on request - response communication. If you tend to focus on the lowest level of programming and forget about the bigger picture, you can easily fall into the trap of incorrect design. You might find that initially everything works as expected but it can quickly turn out that the implemented solution is hard to maintain or extend. I think we can identify at least 2 types of such design traps.
Return channels overuse - Some message brokers allow you to send return messages from the customer to the producer. Using return channels has one important consequence: elements of the system are more linked to one another. This means that you can easily create a situation in which failures in one application may have impact on another application in the system. This in turn means that the system is less scalable and can generate unpredictable behaviors. General prompt: avoid return channels.
Coupling by the message body - You might have a situation in which you want to include a piece of code such as a function or class in the body of a message that you’re looking to send. You can treat such ideas as anti-patterns. This is just another example of the unnecessary coupling of producers and consumers. Messages should be treated as simple data transfer objects - i.e. a description of an action with the necessary raw data. Sending pieces of code to consumers can create a situation in which consumers have to be implemented in the same language, need a particular class or specific package installed. It should not work in such a way.
Summary
As you can see, there are a number of common problems associated with message brokers, which I’ve aimed to highlight in this blog post. Hopefully now that you know how to approach the process of deciding what you need and you know the possible challenges, you’re better equipped to decide whether a queue based system is something that you will implement or not. I hope I help you make a good decision in your projects. Good luck!