Using Machine Learning to Search and Tag Video Footage
27.05.2021 | 4 min read






As Andrew Ng famously said, "AI is the new electricity." Just as electricity revolutionized lives 100 years ago, AI and machine learning are being used in all areas of life today, from medicine through to entertainment. With its incredible potential to compute and analyze huge amounts of data, advanced ML techniques have been put to use by many companies across the world to enable difficult tasks to be completed quicker and more efficiently.
At 10Clouds, we enjoy solving challenges with the use of ML. We recently wrote about how we put it to use to simplify the input of alt texts in our CMS. Today, we wanted to tell you about how we used ML in one of our client projects to process and tag huge amounts of video footage.
Our challenge
SEEEN is a content-as-a-service platform that enables users to split their video into moments and tag them according to their content. Its hybrid headless architecture provides more flexibility and versatility to digital workplace application leaders responsible for customer experience.
Users are able to control all video content from a single hub, publish it to any channel. They can also integrate hundreds of tools with an industry-leading app framework.
SEEEN came to us with the challenge of processing huge amounts of video footage with the aim of then being able to search it (based on both images and audio) so that it would be taggable.

Inputting existing ML models into production
SEEEN approached us with ML models which had already been trained by an external team. The goal for us was to input these into the application and be able to use them in production.
SEEEN’s projects consist of multiple applications which communicate with one another, (including JetStream Pipeline with Model Gateway, Creator Suite and O&O). Each one of them was developed by the 10Clouds’ development team.
The two biggest challenges of the project was the implementation of the framework for processing video and implementing MLOPs techniques to make it easier and more effective to put new models into production and update existing ones.
Searching for the right solution for implementation
We found that there were no existing solutions on the market which would meet our expectations when it came to implementation. That’s why we needed to build our own solution for running pipelines.
We had to work on these solutions in a dynamic way, as the pipelines were reliant on each other, and were in a constant state of flux. We were working towards creating a framework which would make it possible to run custom pipelines (The pipeline consisted of various types of tasks which were dependent on each other and which could have different parameters). Also, the framework should give the possibility to stop or pause the processing and to retry it if there are glitches.
Putting new ML models into production more efficiently
The goal of the data science team was creating a model which generated good results, but this hadn’t yet been tested or built to be efficient. It was our role to do everything possible to ensure that the model was effective and efficient, and after that to implement it in production. The issue that we came across is that this process was very lengthy, so we needed to come up with a workflow which would make the journey from experiment to production more efficient. Here’s where MLOps came in!

Using MLflow
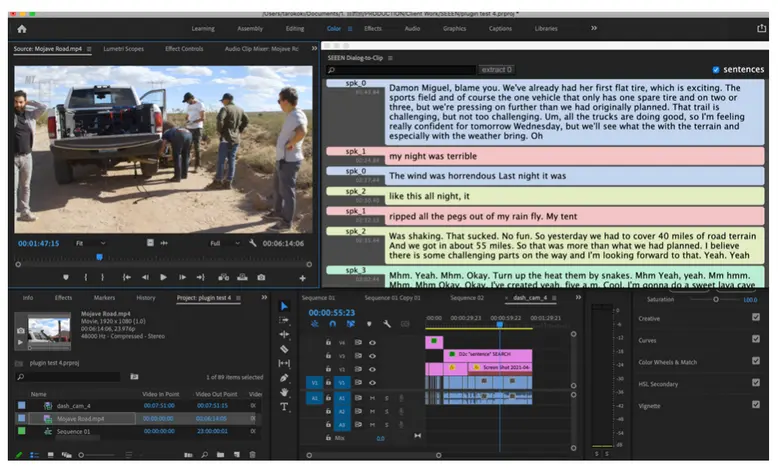
We implemented a centralized tracking server (using mlflow library) to store all experiments along with ready-to-use NN models. The tracking server is used by the DS team to run experiments (when training NN models) and track it’s progress, SEEEN management also can see the current status of various NN models and based on this decide about next steps for the project. We as developers can fetch self-contained models from the Tracking’s server Models registry in our application, and run it independently (thanks to the mlflow framework). The tracking server also does model versioning for us and serves as a storage for model artefacts.
The results
The results of our work were centred on efficiency and productivity:
- The time needed to put a neural network model from an experiment to the production takes significantly less time than when we did it manually.
- The DS team can track experiments and compare them in order to find the best model.
- The managers are able to see the accuracy based on various metrics and the current state of each model used in the project
- The developers don’t have to manually implement models storage, track models versions, deal with models dependencies, etc. The mlflow tracking server and mlflow library in general makes it possible to just fetch the model from the tracking server and run it without worrying about how exactly to fetch the model, how to run it and how to build the environment to run the model.





