AI Recruiter: Natural-Conversation HR Tool Built in 43 Hours
Timeline
December 2025 - December 2025
Type
AI Automation
Industry
hrtech
We developed an AI interviewing system that verifies candidate identity prior to screening interviews. Facial recognition matches live video to application photos within 60 seconds, using anti-spoofing measures to detect impersonators and deepfakes. This process allows companies to identify fraudulent candidates early, saving 30 to 60 minutes per case before recruiters become involved.
Services
Technologies
Our challenge
10Clouds recruitment team hit a wall. High contractor volume created screening bottlenecks. Fake candidates wasted time. English assessments varied by interviewer.
Manual interviews don't scale, but AI interviews fail if they feel robotic.
The hard problems we needed to solve:
- Turn-taking: When did someone finish speaking versus just pausing?
- Speed: How do you respond in under 2 seconds through transcription, AI processing, and voice generation?
- Accuracy: Speech recognition hallucinates when you feed it silence or noise
- Trust: How do you verify identity without friction?
- Fairness: How do you assess language skills without bias?
Generic chatbots don't solve these problems.
What We Built
Voice detection that works
Our first attempt measured audio volume to detect speech. This failed immediately because keyboard clicks triggered false positives, quiet speakers were missed entirely, and background noise caused complete chaos.
We switched to Silero, a machine learning model that detects speech patterns instead of volume. It runs in the browser and filters out non-speech sounds automatically.
We added two-phase processing that starts transcribing at 250ms and confirms at 600ms. This prevents the system from interrupting candidates mid-thought while keeping response times fast enough to feel natural.
Stopping hallucinations
Whisper invents phrases like "Thanks for watching!" and "Subscribe to my channel" when you send it silence or background noise.
We built four-layer prevention:
Only transcribe actual speech patterns
Track when the avatar speaks to prevent echo
Require minimum duration and data size
Clean audio before transcription
This approach reduced false transcriptions by 99%.
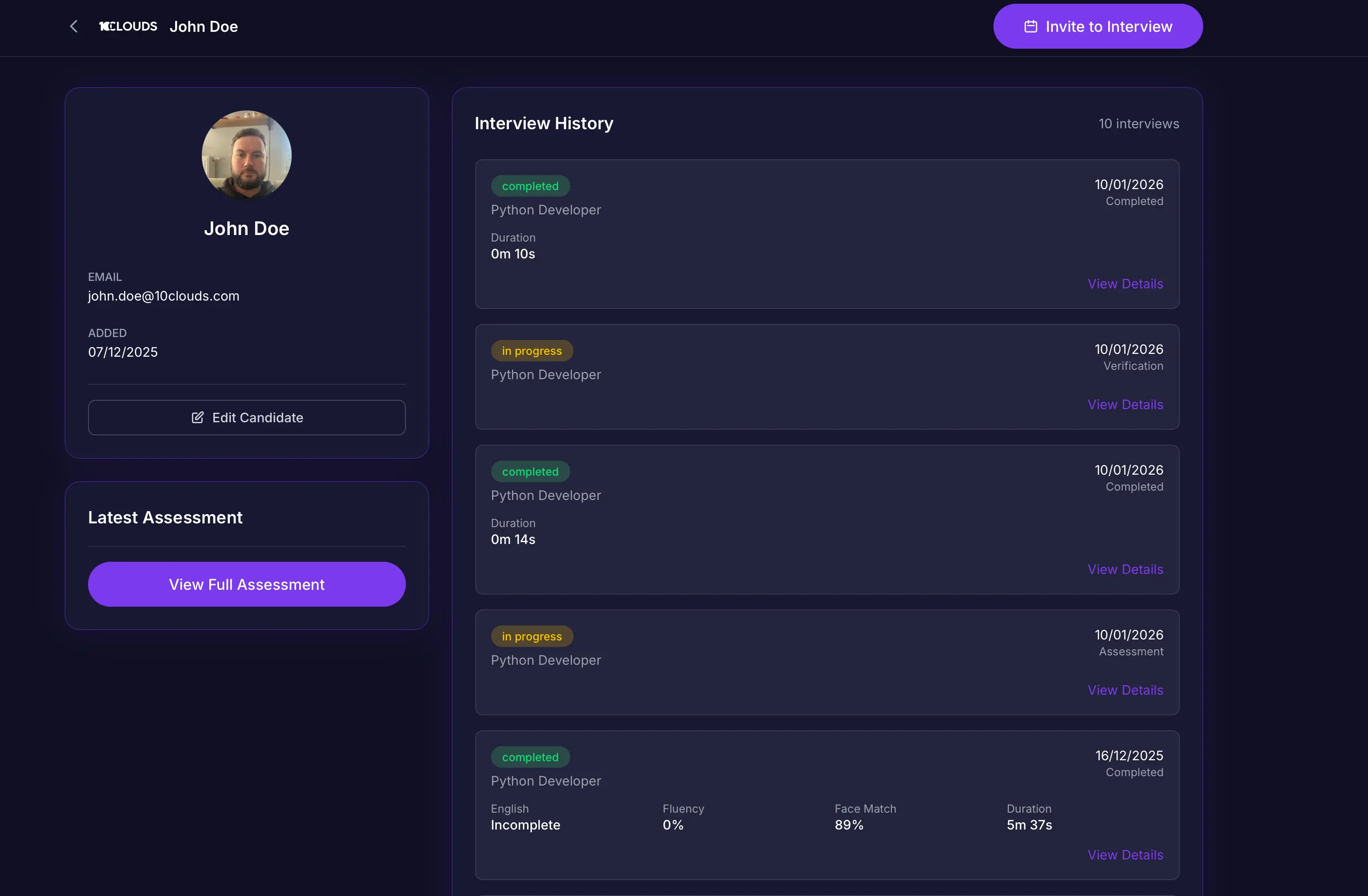
Identity verification
Candidates upload a photo with their application. The system verifies they match that photo during the interview.
We built this using DeepFace and OpenCV so everything processes locally. There are no cloud APIs involved and no data storage issues, making the system GDPR compliant by design.
Anti-spoofing models detect printed photos, phone or tablet screens, video playback, and 3D masks. The system doesn't block real candidates, but it flags suspicious cases for human review.
Fair assessment
- English proficiency
Four questions assess fluency, vocabulary, comprehension, and grammar. CEFR scoring from Beginner to Native.
- Role fit
Three questions about experience and skills. Each references previous answers. Scored on experience relevance, technical depth, and communication.
Questions generate dynamically without templates. Every interview is unique but the scoring stays consistent.
How it works
10-minute interview structure:
Face verification (1-2 min)
Role fit questions (3-4 min)
English assessment (4-5 min)
Company presentation (2-3 min)
Tech stack:
Frontend: Next.js, Silero VAD, D-ID Avatar
Backend: FastAPI, PostgreSQL, DeepFace, OpenCV
AI: Whisper (speech-to-text), GPT-5 (conversation), ElevenLabs (voice)
Two processing pipelines:
- Standard pipeline achieves 1.1-second latency with high accuracy
- Realtime API achieves 250ms latency but with lower accuracy (experimental, disabled by default)
Language support: The system supports 29 languages. We currently have English, Polish, German, Spanish, and Ukrainian enabled.
Built by 10Clouds AI Team • Powered by Claude Code
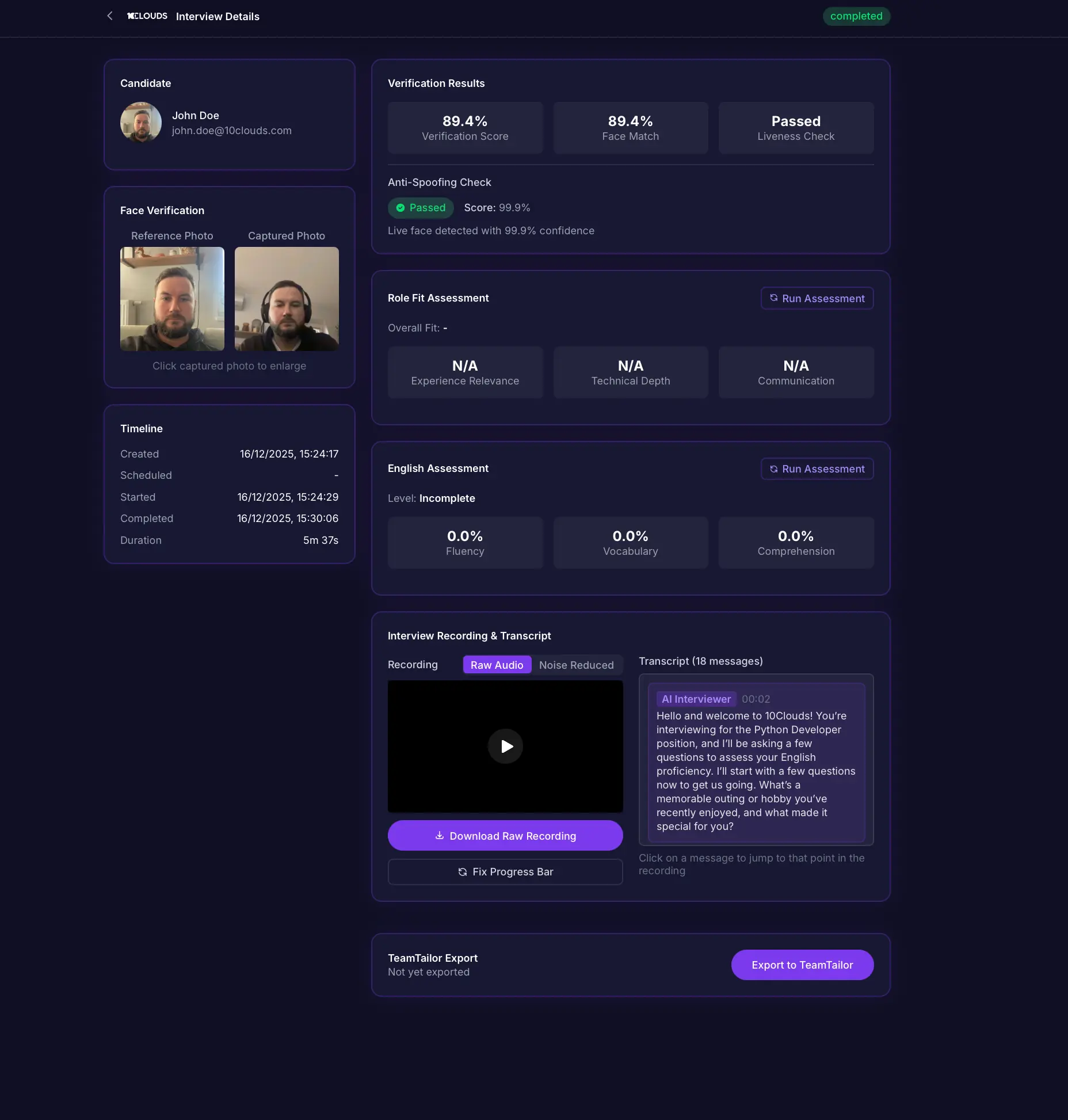
Results
We built this in 43 hours from concept to working prototype using Claude Code.
Technical achievements:
- Reduced speech recognition hallucinations by 99%
- Achieved sub-2-second response time that feels natural
- Reached 85%+ face matching accuracy on real candidates
- Achieved 99.8% anti-spoofing accuracy on live faces
Business impact:
- Automated 10-minute screenings that previously required manual interviewer time
- Created 24/7 availability with no scheduling friction
- Eliminated fake candidates through identity verification
- Removed interviewer bias through consistent assessment
- Standardized company presentation so every candidate gets the same information
Candidate experience:
- Candidates get instant interview access without waiting
- The evaluation process is fair and consistent
- Conversation feels natural instead of robotic
- Candidates receive immediate feedback on next steps
What's Next
We're adding TeamTailor integration for recruiter workflows, creating a custom 10Clouds avatar, building technical coding assessments, developing enhanced analytics, and improving anti-spoofing detection.
Product vision: We're developing a white-label solution for enterprises, building a multi-company platform, creating custom assessment templates, and adding advanced analytics.
Check other case studies
ETS Language Muse
Language Muse is an NLP-based educational platform for teachers working with U.S. students who face the challenge of learning English as their second language.
TimeION
TimeION simplifies the time off request policy and makes the experience pleasurable for both employees and managers.
GoSeqIt
10Clouds provided a platform that allows conducting DNA analysis through the internet, from any place on Earth. It computes and stores all data in the cloud and generates legible reports.
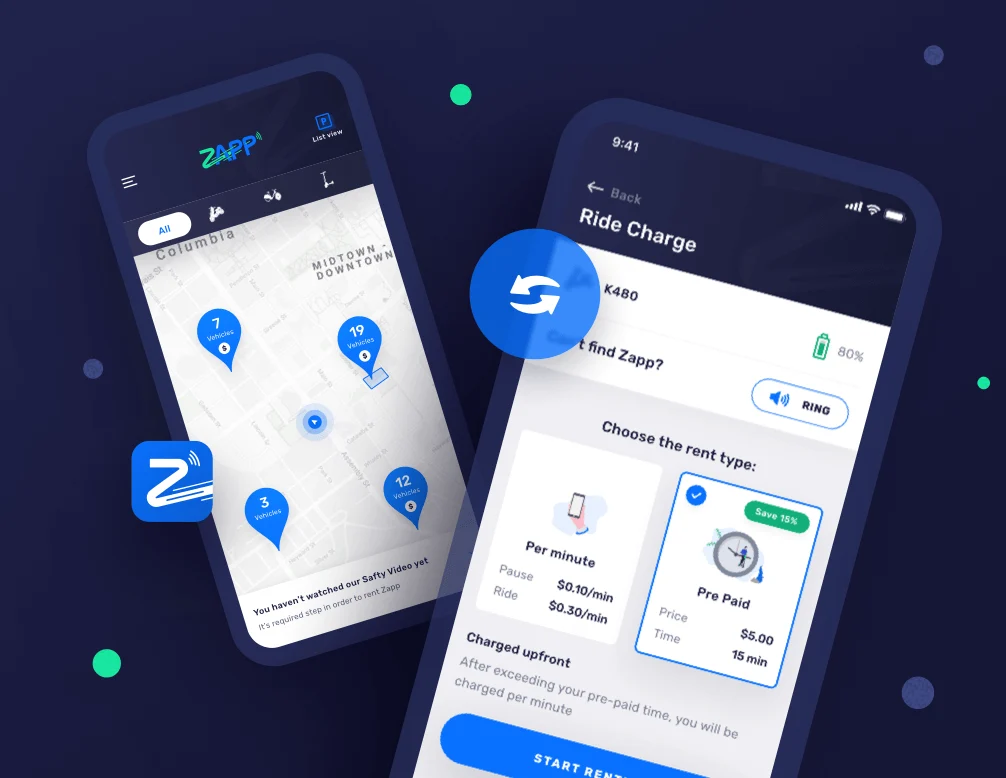
Zapp RideShare
Zapp RideShare is an electric scooter rental service operated with a mobile app. Our team is responsible for the complete product makeover.