NVIDIA Triton — Production-ready model deployment


Machine learning algorithms offer us seemingly endless possibilities in a huge range of fields, including forecasting performance, image recognition, language translation all the way through to playing chess. But even the best, most sophisticated model has limited impact when stuck on a local machine with no ability to communicate with the rest of the world.
The general AI public tends to put the biggest focus and the most resources on the model building process, when in fact this step takes up only around 14% of a data scientist’s time. It’s well known that the often overlooked task of model serving is challenging for many data scientists. It’s one of the main reasons why approximately 87% of data science projects never make it to production (VentureBeat, 2019). And this is exactly where our main protagonist steps in — NVIDIA Triton.
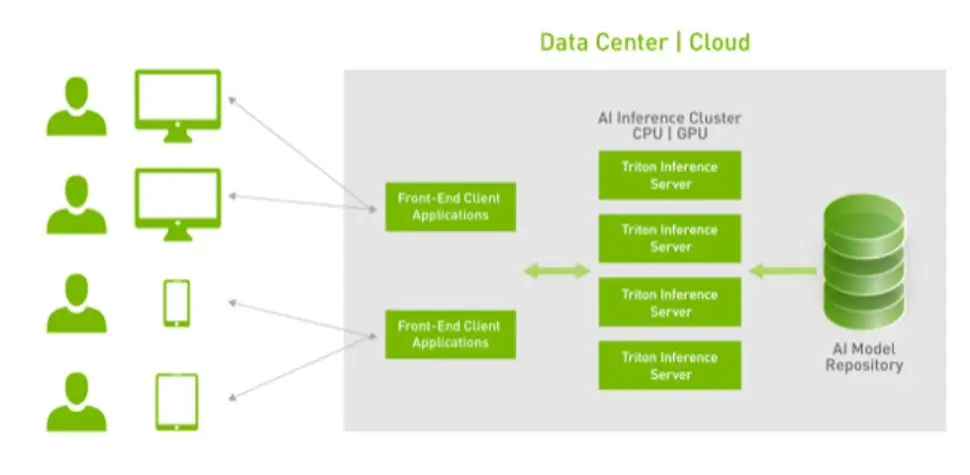
NVIDIA Triton Inference Server — an effective way to deploy AI models at scale
The NVIDIA Triton™ Inference Server is an open-source inference serving software that makes it easy to deploy AI models at scale in production. Currently, there are many different popular approaches to model serving, including: TFServing, TorchServe, Flask and BentoML. But Triton stands out from the competition thanks to its rich suite of features:
- Support for multiple frameworks - Triton Inference Server supports all major frameworks including TensorFlow, TensorRT, PyTorch, ONNX Runtime, and even custom framework backends. Furthermore, Triton is capable of serving multiple models with different runtimes at the same time.
- High performance - Triton runs multiple models concurrently on a single GPU or CPU. In a multi-GPU server, it automatically creates an instance of each model on each GPU to increase utilization without extra coding.
- Scalability - Available as a Docker container, Triton integrates with Kubernetes for orchestration and scaling. It also has access to an end-to-end AI workflow thanks to Kubeflow and Kubeflow pipelines integration.
- Easy deployment - Triton seamlessly loads models from local storage or cloud platforms, so as the models are retrained with new data, developers can easily make updates without restarting the inference server or disrupting the application.
Source: NVIDIA.com
- Cloud-readiness - Triton is supported by Alibaba Cloud, Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), Google Cloud AI Platform, HPE Ezmeral, Microsoft Azure Kubernetes Service (AKS), Azure Machine Learning and Tencent Cloud.
- Flexibility - Triton supports real-time inferencing, batch inference for optimal GPU/CPU utilization and streaming inference with built-in support for audio streaming input. For connectivity both HTTP/REST and gRPC protocols are available.
NVIDIA Triton - Prometheus metrics and the Grafana dashboard
Triton exports Prometheus metrics for monitoring GPU utilisation, latency, memory usage, and inference throughput. This can then be plugged into the Grafana Dashboardfor visualization.
Prometheus is a monitoring solution for storing time series data. Time-series are identified by a metric name and a set of key-value pairs. It offers effective scaling through functional sharding and federation. There are multiple data visualization solutions available, including an inbuilt expression browser and integration with Grafana.
Grafana is an open source analytics and monitoring solution, providing charts, graphs, and alerts for the web when connected to supported data sources.
Both Prometheus and Grafana can bring NVDIA Triton data to life.
NVIDIA Triton - A strong solution for model serving
The process of model serving is crucial while integrating AI solutions with the rest of the system. The choice of proper tool for the task strongly impacts the reliability and user experience as well as accuracy. If you are looking for a strong solution for your project I highly recommend starting from NVIDIA Triton.
Looking for an experienced team to bring your digital product to life?
Get in touch for a free consultation on hello@10Clouds.com. Our friendly team will get back to you within one working day!