7 Things a Startup Should Know About Machine Learning


Nowadays, there is a lot of hype around machine learning, data science, artificial intelligence, deep learning, and the like. If you wonder how it could fit your project’s needs or how to talk to ‘techies’ about it (and understand what they say back at you), or maybe you are a ‘tech person’ and would like to know how to get started in machine learning – hopefully this post would help you with that.
Popular culture pictures machines taking over the world and keeping us all in the Matrix on the one hand, and robots obeying Asimov’s three laws of robotics, working for the benefit of the humankind on the other… Well, we’re not quite there yet. So the first question we need ask is…
1. What is Machine Learning Anyway?
It happens that computers are very good at solving problems that give humans a headache. Complex calculations that can be described as a list of steps and formal rules are what computers excel at. And the opposite is also true: activities that would be trivial even for a child, like distinguishing between a cat and a dog, are a difficult task for a machine. What is the algorithm for that? How to program it? What are the steps and rules for telling a cat and a dog apart?
This is where machine learning comes in. The idea is quite simple: feed the computer with lots of data and have it “learn” from it. What does this learning look like? Let’s say that we’ve collected some data about the hours students spent studying and the final grade they got. Let’s draw a plot for this. It could look like this:
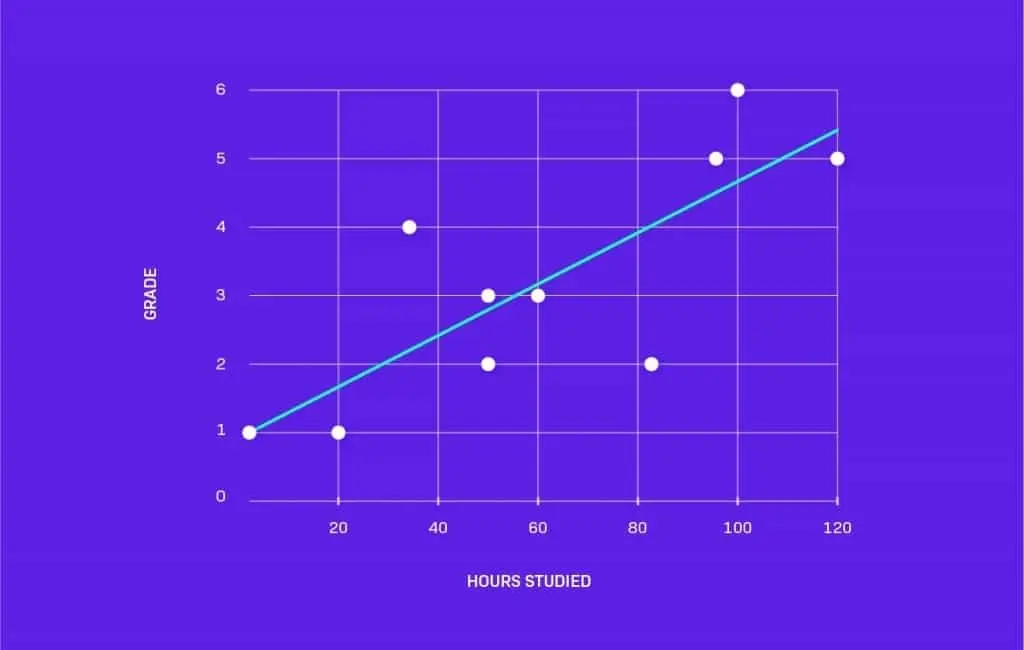
Now we have the computer calculate which line (described by two parameters: its angle and offset) best matches our sample data. And voila, a computer has just predicted our grade based on the number of hours we spent studying.
Of course, in real life, we would have a model more complex than a line. There would be more parameters to calculate, etc., but the principle would remain the same: get some input (hours studied in our example), calculate the parameters of our learning model based on expected output (grade) and then make some kind of a prediction on new inputs using what has been “learned”.
This is called “supervised” machine learning.
2. What is supervised machine learning about?
So, in supervised learning we prepare some input data for a computer to learn from – be it images of animals, emails, or anything else – and each of the images or emails has the correct answer assigned to it (this is a picture of a cat, that one is of a dog; this email is spam, that one is not). This is what “supervision” consists in – we provide all the answers for the training data. And the computer will then calculate all of its parameters to give the expected answer. Hopefully, it will also give the right answer for the data it has never seen before.
The idea behind machine learning is quite simple: feed the computer with lots of data and have it “learn” from it.
What kind of problems could we solve this way? Plenty of them! Problems that require sorting something into a number of groups all belong here. Image recognition, spam detection, content categorization, recommendation engines, targeted marketing, assisting medical diagnosis, predicting epidemics outbreaks, are only some of the potential use cases.
Making predictions of a continuous value (like traffic intensity) is another set of problems supervised learning could solve.
But to do all of that…
3. Give Me More (Tagged) Data!
Quality data is very important in teaching a machine. And there are two important problems to that we will face here.
The first one is: what information should we use as input (data scientists would call it “features”)? Selecting relevant properties of the studied object will be crucial for getting good results. For example, air temperature at the moment of sending an email is quite unlikely to aid spam detection, but it may help predict the number of passengers interested in buying train tickets.
The other important thing is that all that training input should be tagged (i.e. correct answers need to be assigned to it). And we’re talking about thousands or hundreds of thousands, or more of inputs to train the machine and another big batch to test if the training was successful. So someone has to go through all that data and tag it – there is already some potentially significant cost involved, and we haven’t really started with the ‘real’ ML yet.
50% of reCAPTCHA images were used for training machines to read house numbers or OCR texts.
Are there ways to work around these problems? This depends on your use case. There might be some tagged data sets already available (e.g. for image recognition). Or maybe tagging could be crowdsourced… Remember reCAPTCHA? Few people know that only half of the digits or words had to be typed in to pass the test, the rest was used to assist reading house numbers or OCRing texts – a good way to tag data for training machines. But expect investment in preparing data for training.
And is it at all possible to skip the tagging of data?
4. Let’s Leave That Machine on Its Own!
Well… If there is “supervised” machine learning, then there should also be something like “unsupervised” machine learning, right? The bad news is it solves completely different problems, so if you need classification, it will not help you.
But you can still do interesting things without tagged data.
The idea is to feed raw data to the machine and see what it comes up with. The result could be finding some common features among the data and grouping them together (so called clustering); another use case is finding outliers and anomalies in the data.
So the result could be:
- arranging your users in groups (e.g. for marketing purposes)
- social network analysis
- detecting fraudulent bank transactions
- detecting unusual behavior on CCTV cams
- detecting computer network intrusions
- data analysis in bioinformatics
- medical imaging
- market research
- image segmentation
and many, many more. We could even use unsupervised learning to assist finding data features that could be later used in the training of supervised models.
Ok, but where are all the impressive robots we have seen in sci-fi movies?
5. How Do I Teach a Roomba to Move Around?
No, I don’t know if this is the approach they used to create the real Roomba, but if I were designing such robot, I would probably look into “reinforcement learning”, which is another type of machine learning.
How does it work? It’s quite similar to teaching tricks to your dog.
If a robot makes a move and hits something, “oh noes, it’s bad, don’t do that anymore” is the feedback the learning algorithm receives; if it finds a spot with a lot of dirt and cleans it up, it is “oh yes, let’s do more of it, here is the reward”. The machine is programmed to adjust its movements to receive more positive feedback, and the first movements it made might have been random.
Reinforced machine learning is quite similar to teaching tricks to your dog.
This approach does not only apply to robotic movement. It could also assist other machine learning techniques – as long as we can figure out some “environment” that would tell our machines if something is good or bad.
6. Let’s Go Deep!
Neural networks, deep networks, and deep learning are very popular buzz words today, but in fact, any of the above machine learning techniques can be (and have been) done using other techniques.
So are neural networks a brand new thing? No, not at all! I recall reading about them back in the 1990s as a kid. But at that time, home computers (or any computers at all) simply didn’t have enough computing power to make it useful.
Until about the end of the past decade, the statistical approach to machine learning became more popular, but with advances in computing performance and some open source software released, deep learning became available to every Tom, Dick, and Harry.
So what is this mysterious deep learning? Let’s start with a single artificial neuron. This concept is based (yes, you’ve guessed that) on real neurons in our brain.
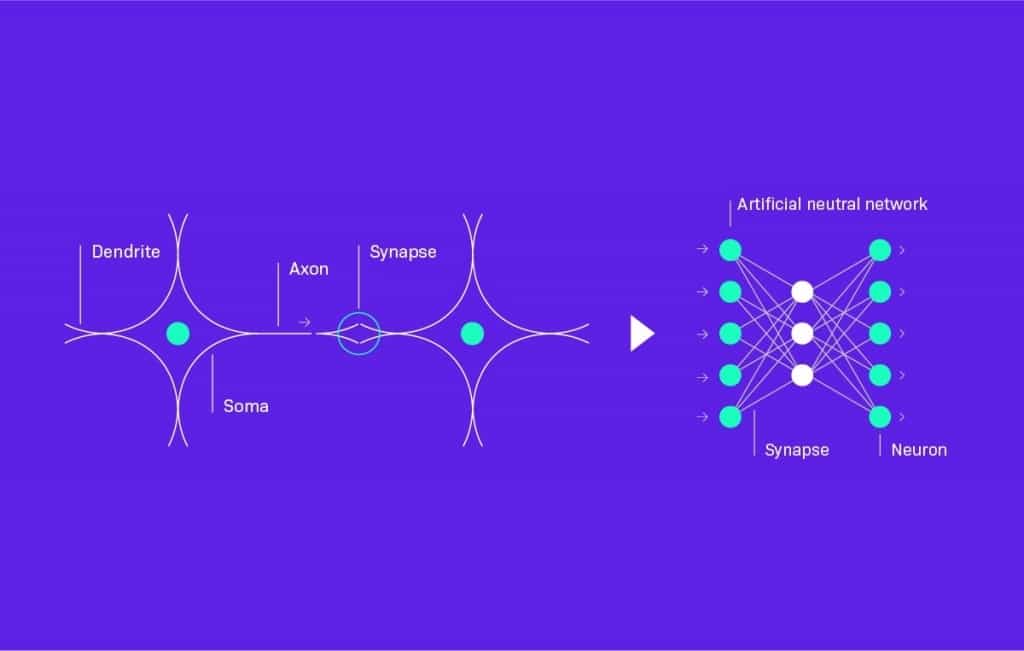
Such a neuron has several incoming connections from other neurons, each of these connections having a different “significance” (or weight as it’s formally called) and some outgoing connection(s) that will fire if the signal on incoming connections (taking weights into account) reaches some level. That’s it.
We then arrange these neurons into connected layers, and deep learning means we have many layers like this. Each neuron in each layer has its weight parameters. All the weight parameters are adjusted to match the expected output (in supervised learning) in a similar manner described when talked about regression finding the best line angle and offset. The multitude of parameters, of course, makes the process more complex and requires much more computations and computing power.
It’s good to have GPUs do all those computations. Recently, Google invented TPUs (Tensor Processing Units) specifically for that purpose. To train the neural network successfully, you’ll likely need some powerful (and costly) computers or cloud solutions.
Is it better to use a neural network instead of simpler approaches? It really depends on the problem there is to solve. For example, image recognition or natural language processing are a good fit for neural networks. Some simpler problems can probably be solved using simpler approaches with satisfactory accuracy and less computing power (and money) spent on training the model.
So what do you need to get started?
7. Tools and Frameworks Out There
What tools are available out there? First of all, nearly every cloud provider, including AWS or Azure, has a “machine learning” solution that claims to be easy to use and ready to be trained. It’s probably a good way to get started – you provide your training data and start getting predictions soon.
The algorithm used in AWS can be pictured as a little more sophisticated version of finding the best-matching line, which is called “logistic regression”. It may be just what you need, but it will likely not be enough for more difficult problems. It’s worth trying, though, and experimenting with it to see what ML looks in practice. Other providers probably use the same class of algorithms in their solutions of this kind.
Other options from cloud providers are instances dedicated to machine learning (e.g. with powerful GPUs and preinstalled ML software). They will probably be more costly than standard instances but can make training machines more effective. And making predictions using a taught model could probably use a regular instance as it requires far fewer computations.
But when we are talking about instances, we need some software, and there is plenty! Data scientists will likely be familiar with scikit-learn, which is good for many solutions, but as of today is not very well suited for neural networks due to its limited GPU support.
Another very popular framework is Tensorflow, open-sourced by Google some time ago. It’s quite low-level, but there are some libraries on top of it that are more friendly, like Keras.
Apache Spark MLlib is another choice, or Microsoft CNTK, or Theano. Caffe is another solution, this time targeted at computer vision.
There are so many good pieces of software out there that the AI can start dreaming of electric sheep.
Looking for a skillful machine learning engineer?
Get in touch with 10Clouds, we’d love to work together!