What Data You Need to Collect in Your Company to Build an MLOps Infrastructure


We know that machine learning has inspired a lot of industries and has actually deep penetrated into their everyday business operations. With implementing ML culture, comes a huge responsibility of designing, implementing, training, testing, deploying, monitoring, and evaluating machine learning models in order to seamlessly experience the end-to-end execution of ML models in the production environment. Therefore, it is high time now to seriously think in the direction of MLOps for the maintainability and sustainability of your ML applications.
In this blog post, we will discuss the prerequisite steps that you should start following from now in order to build an impressive and effective MLOps infrastructure for your enterprise in the near future.
To read more about MLOps, feel free to check out our dedicated blog post on introduction to MLOps.
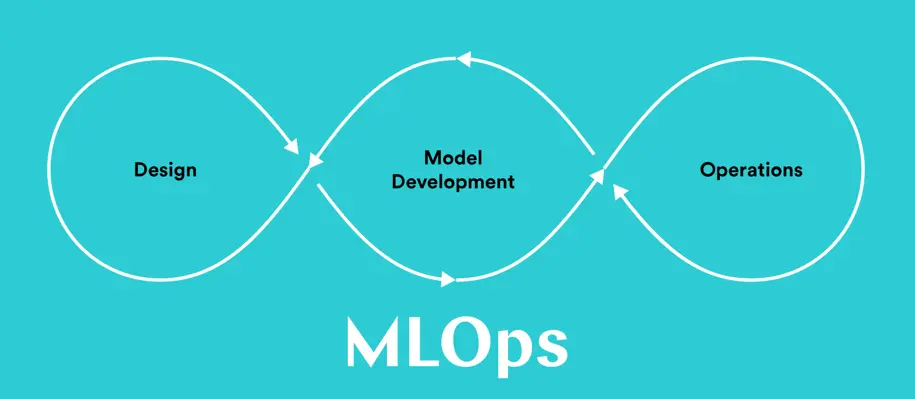
Why MLOps?
As we advance towards following better agile practices day by day, it is extremely important to equip ourselves with modern approaches that actively inspire an agile mindset and culture across the board. Machine learning, today, has produced numerous fruitful applications and it won’t be an exaggeration to mention that we have indeed become dependent on ML, and at this point, even if we just think of removing machine learning applications from our lives, it would look like falling back to the dark ages.
In order to maintain the trust and adopt new changes rapidly, we must implement MLOps and set the path of its automation now. Just like DevOps has brought a revolutionary change in the software engineering industry, MLOps has the equivalent potential to disrupt the machine learning industry by automating, streamlining, and regulating the ML processes.
How to build an MLOps infrastructure
In order to build an effective MLOps infrastructure for your enterprise, you should start diving into exploring the following key factors that play a crucial role while initiating any MLOps procedures.
Identify the stakeholders
MLOps is a distributed concept; it involves individuals from various teams across the organization. Therefore, it is very important to identify the key stakeholders for the kind of MLOps culture you wish to adopt. This is an extremely vital step and must be handled with utter focus and should be backed by relevant business and/or technical research, where necessary. Generally, the following are the most commonly involved stakeholders in the end-to-end MLOps cycle.
- Data engineers
- Data analysts
- Data scientists
- ML engineers
- Software engineers
- DevOps engineers
- QA engineers
- Network administrators
- Product owners
- Product managers
In most cases, ML engineers have the responsibility of dealing with the ML stuff, as well as, managing the software engineering part, followed by the testing but here these stakeholders are mentioned separately in order to address multiple audiences which might have different preferences and definitions of roles. In general, you can eliminate any of the process-owners mentioned above if you think there is an overlap in their responsibilities within your company.
Work towards building the right team

Now that you have identified the important stakeholders, the next step is to reflect within the organization and work towards forming a team that is capable of taking charge upfront. It is very important to build the correct team composition that has the right training and relevant skillset; most importantly a proper communication. It is not always the case that you have the 10/10 manpower right then and there, hence, you should be open to the idea of expanding the team and training the new members in accordance with your business domain.
Research on technical feasibility
Once you have the right mindset and the right teams in place, you should research the technical aspects and identify the tools that you need to use in order to develop a streamlined mechanism. For instance, there are two tools that address the same pain point; Valohai and Kubeflow. Between these two, which tool will be better for your specific use case, that entirely depends on your business problem. Hence, extensive research on technical feasibility is significant.
Apart from the tools and technologies required to address functional requirements, you should also actively think about addressing the non-functional requirements such as hosting infrastructure, network preferences, cloud-native automation, etc. Ever since the emergence of cloud technologies as a service (AWS, Google Cloud, IBM Cloud, etc), the deployments and automation pipelines are easy to manage and we encourage using them rather than recreating the wheel. In general, the motive should be to invest time and money in the right kind of infrastructure.
Automate flows and processes

Earlier, we discussed the thought processes and approaches involved in order to develop an MLOps mindset. From this point onwards, we will look at the actual implementation side of things and how to rapidly grow MLOps pipelines and processes.
By now you might have already realized it but before we move on, it is necessary to recall that although MLOps is an iterative process, it is yet a strictly sequential paradigm in which the order of processes matters a lot. You cannot skip or tailor any step in between; if you do that is the biggest mistake!
Following are some of the key areas that we need to automate using relevant tools.
- Data collection
- Data analysis
- Data engineering
- Experimentation
- Modeling
- Training
- Testing
- Monitoring
- Version control
- Packaging, containerization, and orchestration
In a traditional DevOps environment, we do continuous integration and continuous delivery; CI/CD in short. When it comes to MLOps there is more to it i.e. continuous testing. In this situation, we should implement the flow of CI/CD/CT and use tools to automate them as a whole.
MLOps facilitation tools
Following are some of the commonly used tools out there in the industry that help in automating processes and ML pipelines.
- Data Version Control — DVC is a tool that helps you in experimenting with your ML pipeline, track outcomes and metrics, and facilitate in versioning of data. Data versioning is exceptionally important because you need to define a clear distinction for the new data flowing in that your business might be producing.
- Kubeflow — is a tool that contributes to packaging, containerization, orchestration, and deployments of machine learning systems.
- Polyaxon — is again a tool to help with orchestration and managing the entire life cycle of ML systems.
- MLflow — helps in maintaining the system life cycle and organizing experimentation and deployments.
- Comet — is an interesting tool that helps you visualize all your experimentation analysis and results in a single place.
- Optuna — when it comes to automatic tuning of hyperparameters based on the validation logic, Optuna is the go-to tool.
- Cortex — a powerful tool for serving ML models on top of AWS services.
- Seldon — helps in deploying models on Kubernetes.
- Amazon SageMaker — after training, testing, and deploying the model, the job is not done. There has to be a continuous monitoring mechanism that keeps a check on the quality and performance of the model in the production environment. SageMaker is a tool that does exactly that.
Conclusion
MLOps is the future. A lot of time-consuming and manual processes can be automated using MLOps tools and strategies and hence the eventual goal of the system sustainability, maintainability, and availability can be achieved. In this blog post, we discussed some strategies, tools, and technologies that you, as an enterprise, need to follow in order to provide an effective MLOps infrastructure for your business. We look forward to wonders that you can pull off with MLOps.
Looking for an experienced team to bring your digital product to life?
Get in touch for a free consultation on hello@10Clouds.com. Our friendly team will get back to you within one working day!