Two Examples of Amazon Mechanical Turk Usage That You Didn’t Know About.


Often we’re asked about use cases that can be executed with success on Amazon Mechanical Turk. I’ll write a bit about two of our implementations that have worked quite well. But first, what exactly is crowdsourcing?
According to Google: „obtain (information or input into a particular task or project) by enlisting the services of a number of people, either paid or unpaid, typically via the Internet.”
That’s actually a fairly good definition. In our line of work, we focus mostly on the paid part that you would define as micro tasks and can see in action on services like Amazon Mechanical Turk.
Around 2011 we started developing crowdsourcing software. At first those were simple applications that powered workflows built from one or two steps, such as obtaining a url for a given topic or filling in some missing data for a record. With time we’ve gained experienced and started developing much more complex solutions spanning dozens of workflow steps.
We’ll share some of our more interesting crowdsourcing workflows that we’ve developed over the years. But first…
What is a Crowdsourcing Workflow?
Crowdsourcing workflow is a set of tasks executed by crowd workers on services like Amazon Mechanical Turk, CrowdFlower, and oDesk, or through an internal workforce. Those tasks can be augmented by automated functions like quality control, image recognition, natural language processing, or others.
Before sharing with example workflows, I’ll explain some of the main building blocks that we are using when building workflows:
Transcribing BIB Number / Starting Numbers
Imagine a sporting event like a marathon or a cyclist race where there will be thousands or tens of thousands of photos, and nearly every attendee would like to obtain his or her photo. In those types of events, all the participants have some kind of ID on their T-shirts, so in most cases it’s just a matter of transcribing all the visible numbers on the photo.

Computer vision works to a point but will not yield 100% accuracy. Searching through those photos using only event organizer staff will take a lot of time, so it’s much easier and cheaper to complete this task using crowdsourcing. We’ve done a lot of such jobs for Tagasauris a human assisted computing platform.
Here’s an example workflow design that yields good results. This is actually a new version of the workflow based on experiences from the original task that was running some time ago:
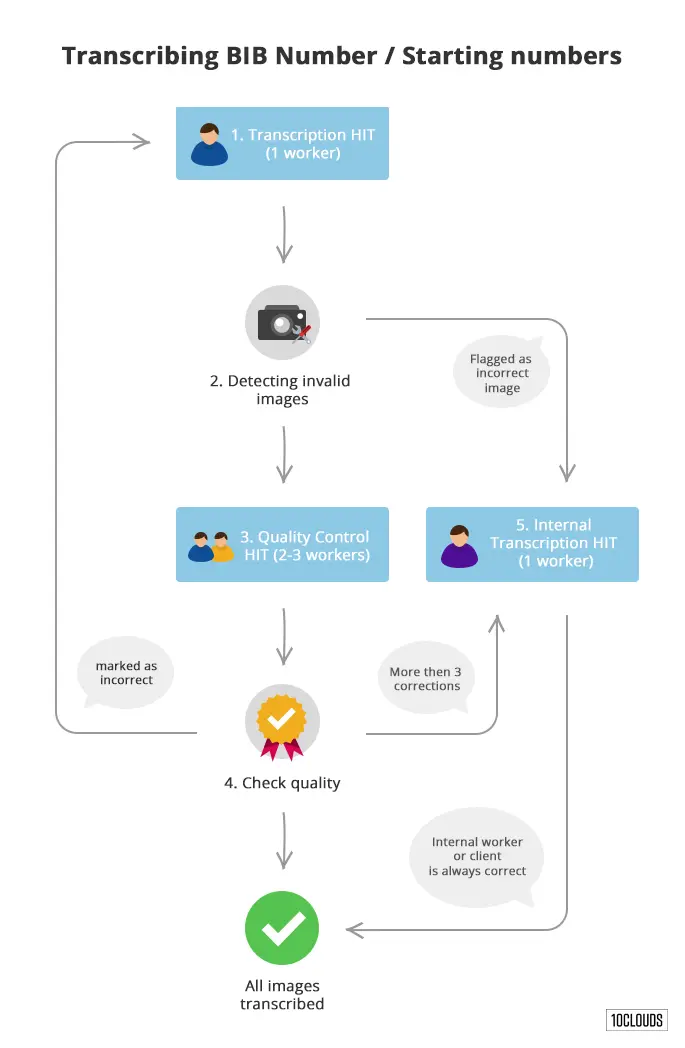
Let me walk you through the particular steps:
Transcription HIT.
Workflow starts with a HIT where a worker can see the photo in question and enter multiple entries in an input box. Every photo gets annotated by one worker with the assumption that he or she will do a good job. If there’s something wrong with the image, it can be flagged as incorrect.
Decision 1.
This is a simple decision step. Any images flagged as incorrect are forwarded for moderation by internal workers. Remaining images are sent on to quality control.
Quality Control HIT.
Here, two or possibly three workers judge each transcribed entry until there’s majority, so either a 2:0 or 2:1 result. Mind that we don’t always need three workers for this task; this is a neat cost optimization.
Decision 2.
If more than 50% of the numbers transcribed were marked as incorrect by our quality control, we mark everything as incorrect and ask another worker to transcribe that image. If more than three workers have already worked on that one image, we push it to Internal Transcription HIT as there’s most likely something wrong with it.
Internal Transcription HIT.
Internal means that either the end client or some trusted worker checks the images that had quality problems. We trust all of these results.
Quality control steps here are essential if you want > 90% correctness rate. With tens of thousands of images, you will come across various problems along the way.
Translating Text Using Crowdsourcing
This is an extremely interesting problem. Even though automated translators can provide understandable foreign language translations most of the time, they don’t do a good-enough job. For some time now, we’ve been working on a site called Crowdtrans.com, which performs translations using Amazon Mechanical Turk. Currently it’s used mostly for gathering training data for more exotic languages for machine learning, but in most cases it generates better translations than machine translators and it’s less expensive than normal translators or similar services.
Here’s an overview of the workflow we are using there:
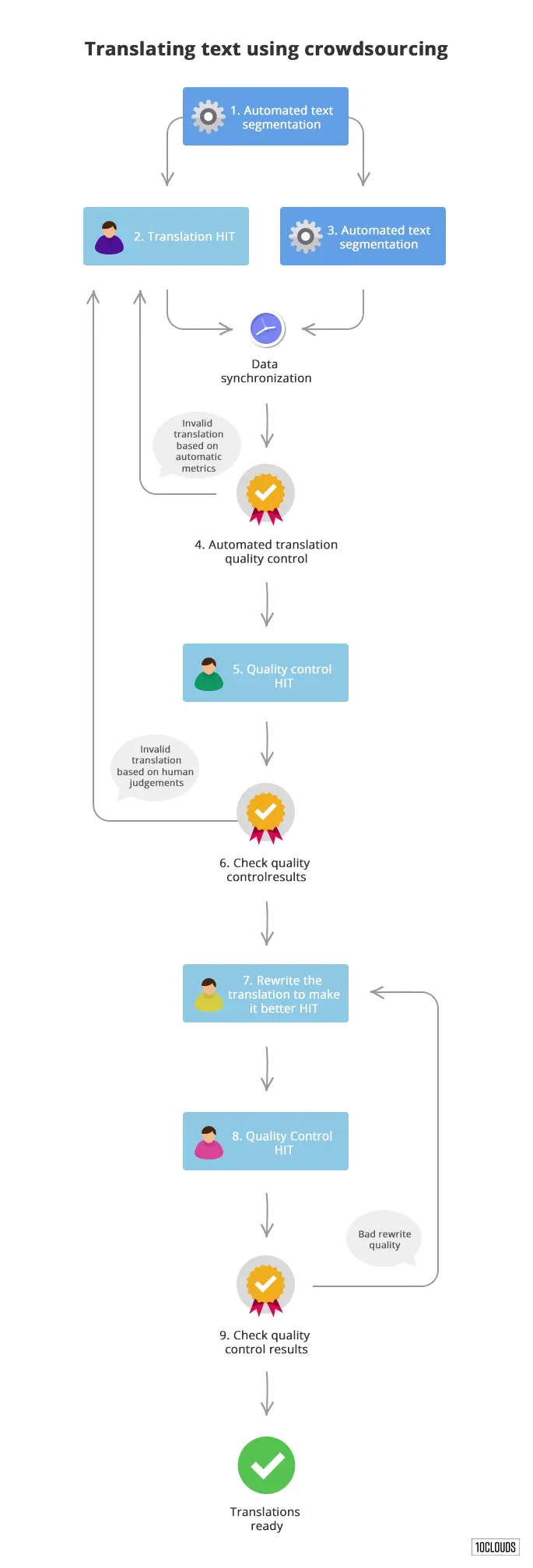
So here’s what’s happening:
1. First step is a proper segmentation of the input text into multiple sentences that can be translated independently.
2. & 3. We start with two tasks working in parallel. One is a simple translation HIT that’s posted to Amazon Mechanical Turk where workers transcribe a single sentence to a target language. The second task is a machine translation task that runs our sentences through Google Translate and Bing Translator to gather reference data that we’ll use later on for our quality control metrics and spam detection.
4. Quality control in the case of translations is trickier than just checking if someone transcribed the correct number. What we do is use multiple checks to validate whether the worker translations are similar to the machine translations and determine whether the sentence looks correct in the target language. We then do some more magic under the hood. Any translations that don’t meet our guidelines are send back for re-translation.
5. Finally we do quality control by humans. Here we use native speakers of the target language. This can be enforced by proper usage of Amazon Mechanical Turk qualifications tests or pre-screening on your own. Workers are asked to score a given sentence or mark if it looks like spam or machine translation.
6. If the sentence’s score is too low or it is marked as spam or machine translation, we send it back for retranslation.
7. At this point we have a decent translation that we want to be a bit better. We ask a native speaker to fix any interpunction, style issues, etc.
8. We do the same type of quality control as we did on step 5.
9. If the average score is still too low, we send the translation for another set of corrections. If everything is fine, the translation is complete.
Afterthoughts
The transcribing BIB numbers example could also be generalized for other use cases such as transcribing business card data or receipt data.
You can imagine a much more complex process working on Amazon Mechanical Turk or spanning multiple crowdsourcing sites. Such workflows can involve annotation of data in multiple steps, with decisions being made based on quality metrics gathered along the way.
As you can see on the examples we’ve provided, there’s also no reason why you can’t combine human workers with computer algorithms in various ways to optimize cost and speed.
And of course if you are in need of processing vast numbers of images or translating text you should visit Tagasauris.com / CrowdTrans.com