How to Extract Complex Data with Crowdsourcing
20.11.2014 | 4 min read







Labscholars.com is a comprehensive search engine that is dedicated to helping researchers to find and order scientific equipment and supplies. It allows users to search, browse and share knowledge, experiences and scientific results on a global scale, making an impact on the online research community. The platform itself has been developed by 10Clouds and we’ve faced several interesting challenges during the development process.
One of the obstacles that we encountered during the implementation of the search engine and the backend was how to uniformly enrich particular inventory items with additional details such as technical specifications.
The LabScholars proprietary data crawling solution is able to find product names, suppliers and basic category information but getting technical specifications is difficult since every producer and provider presents the data in different shapes and file formats: PDF files, scanned documents or HTML tables are just a few examples of the variations provided. This fact presents a problem, since creating automated extraction tools is very consuming in terms of time and money and those two factors are often limited in an early stage startup.
This is where the phenomenon of crowdsourcing, one of our particular fields of interest and specialization at 10Clouds comes into play. According to Oxford Dictionary Crowdsourcing is: “Obtaining (information or input into a particular task or project) by enlisting the services of a number of people, either paid or unpaid, typically via the Internet.”. The definition of the word is quite simple, yet in our case it precisely illustrates the main idea of gathering people (Crowds) to complete tasks that artificial intelligence cannot (At least yet) complete.
One of the scenarios that LabScholars wanted to support was the ability to enrich user-requested or popular items with additional content. To enable this, 10Clouds devised a process powered by crowdsourcing to accurately gather technical specifications for LabScholars inventory. This process is independent from the main website and can be activated via one of the most popular platforms for these types of tasks: Amazon Mechanical Turk.
To explain and illustrate even further let me show you a simple screenshot of an inventory item without any technical specifications:
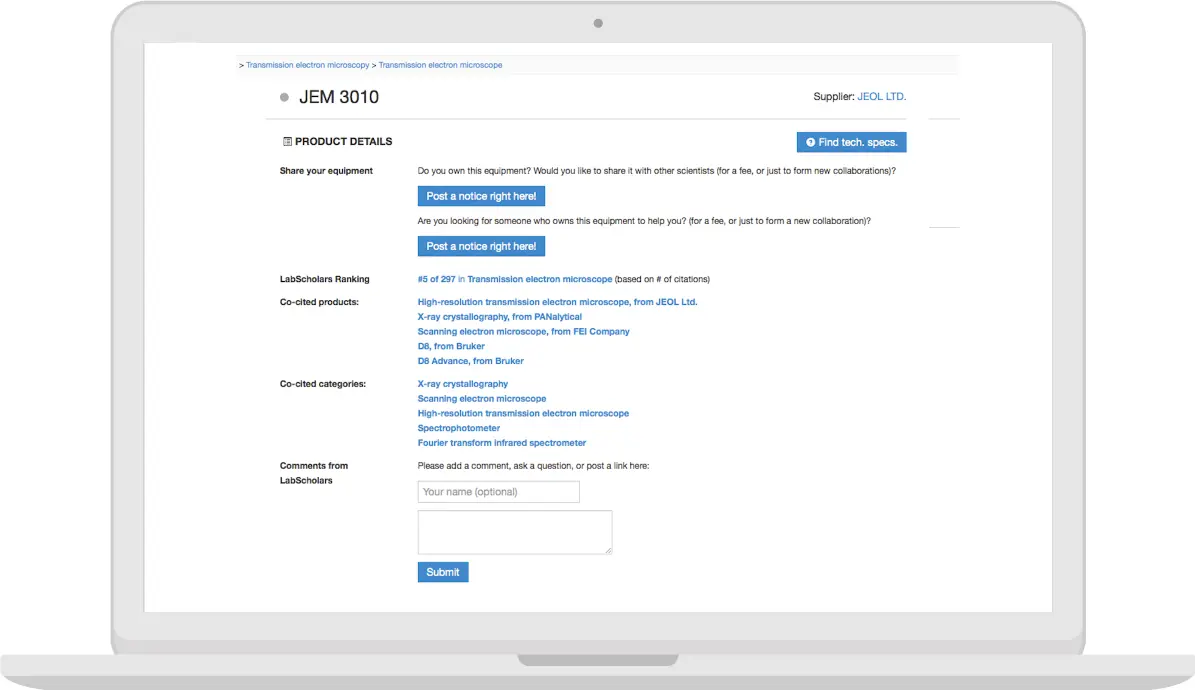
Before data enrichment:
Example item before data enrichment: We are able to show only the category, supplier and recommend some relevant inventory items.

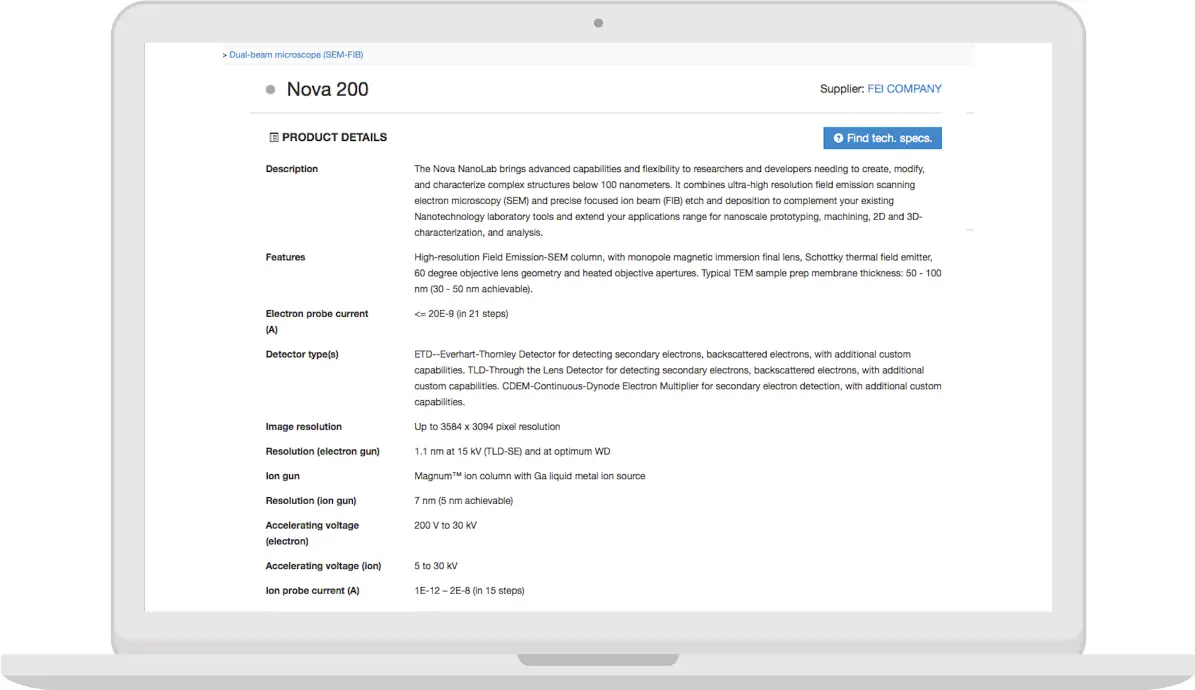
After data enrichment:
We can show the entire technical product specs. For this particular example the data was fetched from a source page.
The Solution
How can we do this at scale? We have devised a workflow similar to the ones described in my previous blog post about crowdsourcing. The flow in mention verifies that the workers are providing data of good quality and not spamming us with bad information.

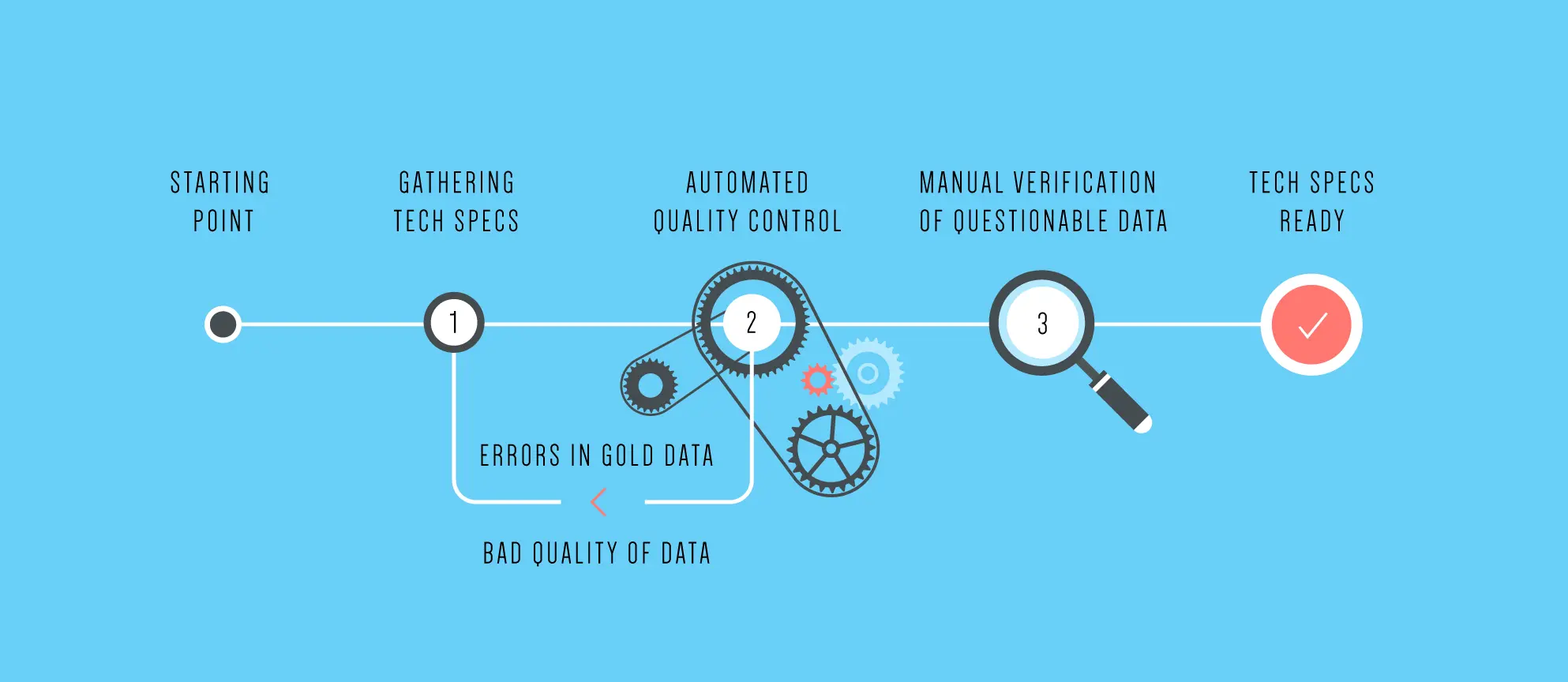
1. The first step is a HIT that gathers technical specifications in a format dependent on the category of the inventory item. In this step there is a lot of basic validation and we also include gold data to verify that workers aren’t gaming the system. For each item we get answers from two to three different workers to ensure that the quality is kept at a high level. Here’s an example of how this HIT looks like:

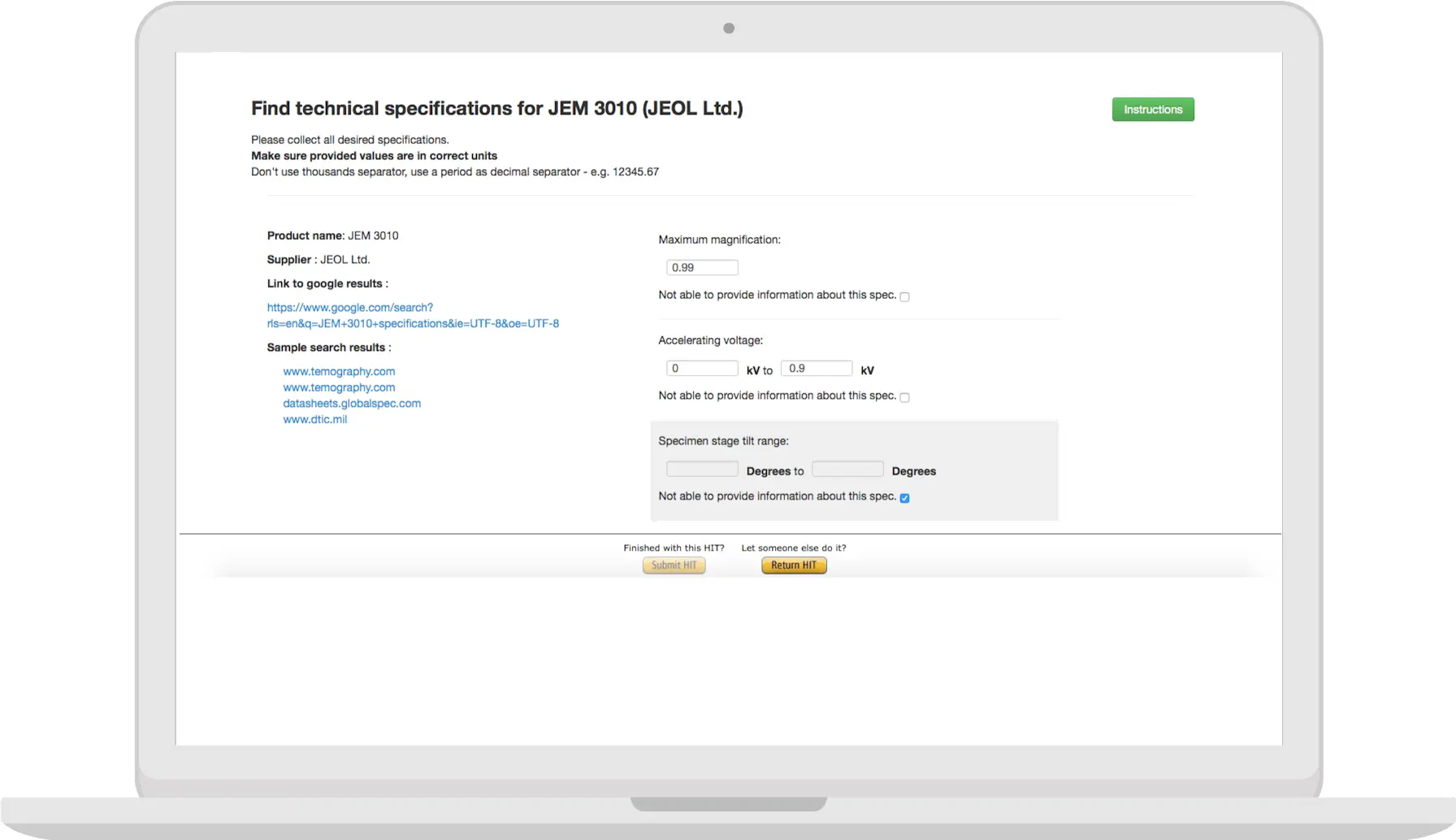
2. The second step is an automated quality control where our system checks the quality against gold data and verifies that there’s an acceptable ratio of tech specs that were found versus those marked as not available. This takes place both on the level of a single item and through all of the given worker’s submitted materials.
3. The third and final step is a validation by admins of items that have been automatically marked as borderline: Sometimes workers don’t agree on one particular tech spec and it makes sense for us to validate it. In the future such a task could be completed by workers that are trusted based on their prior performance.
Afterthoughts
What’s nice about this is that now LabScholars has the capability to enrich their inventory in an affordable way that would not be possible at scale without the tools mentioned in this blog post. This approach is also a great step towards improving the tools for both automatic item enrichment and the automatic cleanup of inventory data. You can easily imagine that similar tasks could be created for Mturk workers to verify items that were reported as incorrect, without the need to involve LabScholars staff.




